I suppose this is the inevitable follow-up to my So I bought a PHEV post from 2021.
In September, I bought a Hyundai Kona EV.
The number one question/concern I received from most people is how the hell I was planning on surviving in Winnipeg’s notoriously cold and brutal winters in a battery car.
The short answer: it’s not a big deal for me.
The long answer: it might be for you, but that depends.
We’ve had a solid couple of months of winter, including a solid week below -20. I’ve been collecting some data1, and taking note of my subjective experiences.
Heating
I suspect some of the skepticism I’ve heard is driven by the fact that resistive electric heating is extremely inefficient! If you’ve ever had electric baseboard heating your winter bill will leave you with a profound understanding of this fact. It seems like it would drain the battery at an impossible rate.
However, EVs sold in Canada are equipped with heat pumps! Heat pumps are magic: they are up to 4x more efficient than resistive heating2.
Not only are they more efficient than dumping a bunch of electricity into resistors, they start generating heat in under a minute. So there’s no warming up the engine for 15 minutes before it starts heating in the bitter cold.
The Curious Relationship Between Heat & Distance
I’ve observed an interesting relationship between heat and distance.
Energy consumed to heat the car’s interior is time-based. It takes a certain amount of time to raise the temperature inside the cabin. The heating system initially uses a large amount of energy and then decreases the energy as the car warms. The amount of energy devoted to heating is almost a fixed average over time.
Energy consumed to move the car is a function of speed and distance. Obviously sitting at a red light doesn’t consume any energy3.
So if you’re stuck in traffic in -20 for 20 minutes driving only a few km, the drivetrain might have only consumed under 1kWh but the heating system may have spent 2 or 3kWh.
This has the counter-intuitive effect of increasing efficiency (to a point) the further you drive. Seeing the km/kWh number go up as I get closer to my destination is a trip!
Regardless, even with a heat pump, heating has a huge impact on range!4
Battery Heating
Another factor mentioned by skeptics was the performance of the battery at colder temperatures. And in this regard, the skeptics are right.
Lithium-ion batteries have a sweet spot between 20º – 30º and are thermally managed to keep them there5.
In other words, at a certain point the battery begins to spend energy heating itself. I guess the engineers have determined the point at which the loss of performance due to colder battery exceeds the energy cost of heating itself.
In my experience, the point at which this system kicks in is entirely unpredictable. So it’s not necessarily reasonable to avoid driving at -25, for example.
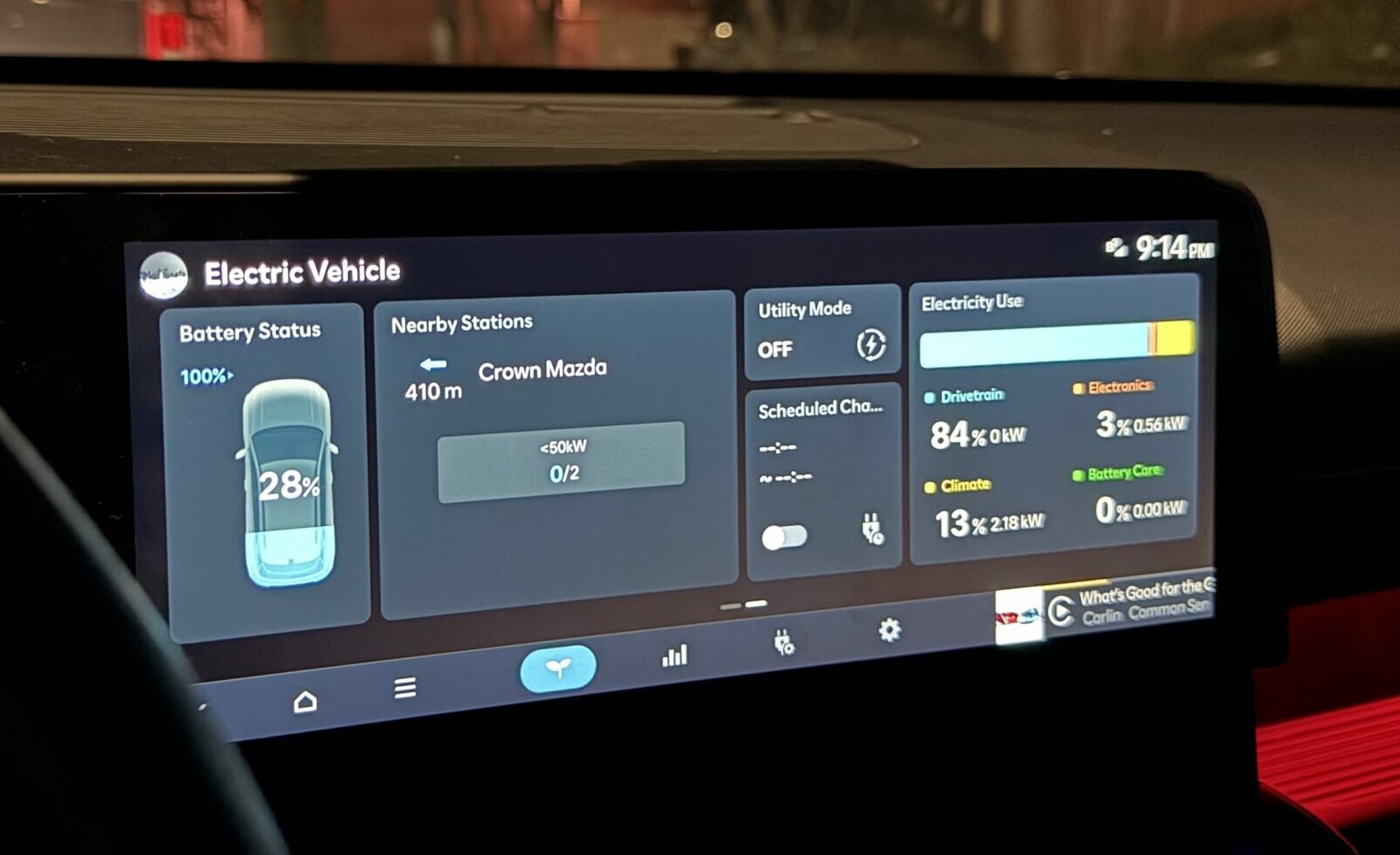
Battery Percent Oddity
On a particularly cold day this month, I parked in a heated garage for about an hour. When I got back into the car, to my surprise the state of charge had decreased by about 20%!
Thinking about this logically, I believe what’s happening here is that Hyundai is choosing to represent the battery % as a factor of all the cold-related physics that decrease battery efficiency and effectively make fewer kWh available.
So when the battery is cold, it’s effectively smaller. And when it warmed up inside a garage, it’s effectively bigger. The amount of energy stored in the battery didn’t change, but the amount available for use (the denominator in the equation) increased.
That’s just a theory.
The Numbers
The Kona EV is advertised as having “approximately 420km of range.”
The actual numbers from Natural Resources Canada6 work out to:
- City: 347km
- Highway: 288km
- Combined: 314km
Hyundai’s marketing number seems wildly optimistic!
City
My city driving efficiency varies a great deal.
I’m seeing individual trip efficiency anywhere from 1.6km/kWh (just over 100km range) on very short, cold drives. To 4.1km/kWh (264km) on longer drives across the city.
The main factors affecting this efficiency seem to be:
- Distance of trip: very short drives consume a large percent of energy on heating and so decrease the per km efficiency dramatically.
- Length of stops: if you stop long enough for the battery to cool down, the car may reengage battery heating once you’re underway again.
- Traffic: slow traffic means more watt-minutes devoted towards heating when you’re not moving.
There was one extremely cold Saturday where I spent 50% battery just running around the city. I don’t think I drove more than 50km but I had to drive cross town in slow traffic and I was stopped 30 – 60mins+ at two or three destinations.
Worth noting that in my car co-op experiment, I found that most of my trips are quite short. So I think I might be seeing worse average efficiency than someone who commutes for 30 minutes every day.
Highway
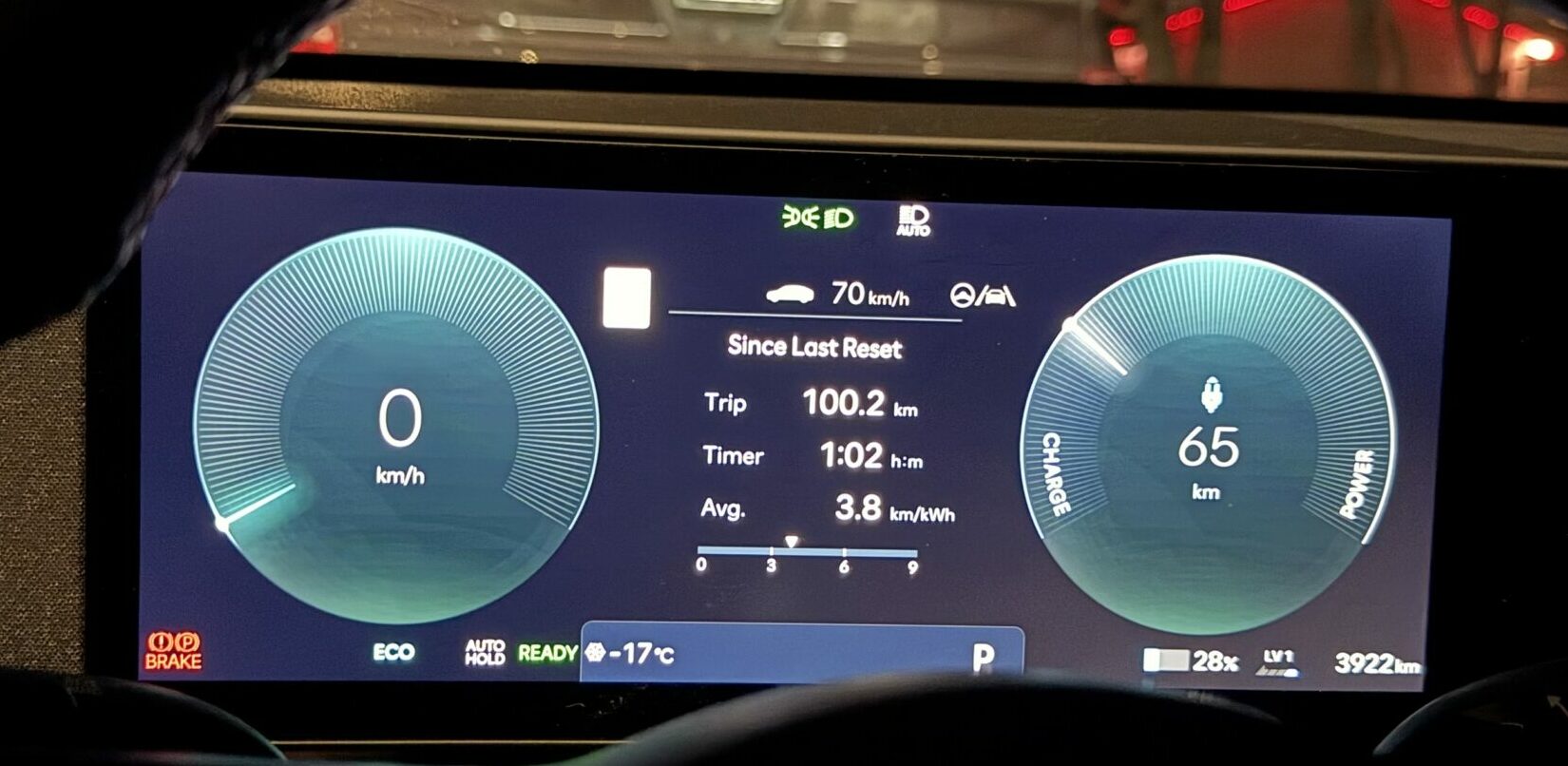
For the purpose of collecting data for this blog post, I did a 100km loop on the Trans-Canada highway at an average speed of 100km/h.
Outside temperature was -17. I set climate control to automatic at 19.5. This was on all season tires, properly inflated to 35psi. I was the only passenger7.
I recorded an average efficiency for that trip of 3.8km/kWh (so 245km range).
Other observations:
- I did not record the wind speed or direction, but I recorded a 0.4km/kWh efficiency difference heading west vs east.
- The battery heating system did not engage at any point during the trip.
- This is obviously much more efficient than what I’m seeing in driving in the city.
I don’t have concrete numbers from warmer temperatures yet. But this feels roughly in line with a trip to Brandon that we took in October.
Charging
Charging is extra relevant to the winter equation because the car consumes more energy during the winter. So this section is not really winter specific, rather it’s more a report on the state of things in and around Winnipeg in 2025.
A large factor in my decision to buy an EV was convincing myself that I would be able to get by on only level 1 charging8 at home.
In terms of my own experiences this winter, it has been going OK. The math of it all is pretty silly: charging 1% at level 1 takes around 45 minutes. So for example, if I spend 2% heating the car before I leave, that’ll take an hour and a half to recoup later. But I haven’t felt the need to visit a fast charger.
Cost
A huge benefit of charging at home is the cost. Manitoba Hydro currently charges a flat rate of $0.095/kWh. Math that out and charging the car’s 64.5kWh battery from 0-100% would cost a total of $6.128 (plus tax).
In terms of real numbers, my electrical bill for November and December were both roughly 400kWh more than last year. In other words, it’s costing me $38/mo to drive my car in the Winter. That’s almost entirely city driving, about 1200km/mo.
Infrastructure
Technically, there are 123 publicly accessible chargers in Winnipeg if you count everything9.
While that sounds like a lot, a large number of these are semi-private, either: at car dealerships, attached to apartment buildings — you could probably use these in a pinch but I assume it’s frowned upon — or paid parking lots.
In reality, I’ve only happened across maybe a half dozen (or less?) chargers that are actually near a destination I intend to visit. That’s not great.
Fast Charging
Fast charging is where the infrastructure is currently lacking the most.
Excluding dealerships, there are only 13 charging locations that offer > 50kW (5 > 100kW) in Winnipeg.
That’s not great.
Outside of the city there are 23 > 50kW (9 > 100kW). None of those are to the east.
If you’re thinking of heading out of town, you’ve got to do a lot of pre-planning. And in the winter, with the possibility of being stranded in the cold. That’s a little scary.
Verdict
The bottom line for me is: city driving an EV in a Winnipeg winter is not a big deal, at all. In fact, the nearly instant heat is almost reason enough to switch to an EV! Not to mention the extremely low operating cost.
Highway driving in a Manitoba winter becomes a little more iffy but that’s more of a function of poor state of the infrastructure.
None of this matters
But thanks for reading. Ha.
Let’s ignore the highway driving situation, since it is currently so infrastructure limited and just focus on the city driving question.
Range is basically irrelevant. Even at my extreme worst case scenario of 1.6km/kWh, that’s slightly over 100km on a full charge. I don’t think I’ve ever driven 100km around the city? But if I did, I could find a fast charger.
The real question isn’t range. It’s this: can you meet your daily driving needs by charging at home?
For me: the answer is a resounding yes. But I work from home and live in a reasonably walkable neighbourhood, and there are some days the car doesn’t even move.
For you, it depends.
If you have a longer commute, relying on level 1 charging during a week-long Winnipeg cold snap would be challenging. As your daily usage exceeds the range gained by charging over night, you’re gradually slide closer to 0%. Worst case scenario you might have to find a fast charger once or twice that week. In my opinion, that’s still not really a big deal.
On the other hand, if you have a longer commute and a bunch of additional errands that are far-flung, you might find yourself cutting it close to 0% on a very cold day. If that’s your reality, then yeah — maybe an EV isn’t the right fit right now.


{kind=link}
{kind=link}